In den vorherigen Kapiteln haben Sie einzelne Elemente vom Typ int, char oder andere
Einzelobjekte deklariert. Oftmals wünscht man sich aber eine Sammlung von Objekten,
wie etwa 20 Ganzzahlen oder ein Körbchen voller Katzen (CAT-Objekte). Heute
lernen Sie,
Ein Array ist eine Zusammenfassung von Speicherstellen für Daten desselben Datentyps. Die einzelnen Speicherstellen bezeichnet man als Elemente des Array.
Man deklariert ein Array, indem man den Typ, gefolgt vom Namen des Array und dem Index schreibt. Der Index bezeichnet bei der Deklaration die Anzahl der Elemente im Array und wird in eckige Klammern eingeschlossen.
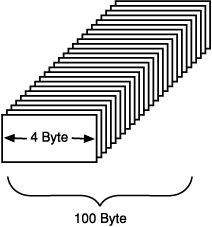
long LongArray[25];
ein Array namens LongArray mit 25 Zahlen des Typs long. Der Compiler reserviert
bei dieser Deklaration einen Speicherbereich für die Aufnahme aller 25 Elemente. Da
jede Zahl vom Typ long genau 4 Byte erfordert, reserviert diese Deklaration im Speicher
100 aufeinanderfolgende Bytes (Abbildung 12.1).
Abbildung 12.1: Ein Array deklarieren
Auf die Elemente des Array greift man zu, indem man einen Index als Offset (Verschiebung)
vom Array-Anfang angibt. Die Durchzählung der Array-Elemente beginnt
dabei mit 0. Das erste Element des Array ist demzufolge arrayName[0]. Für das LongArray
-Beispiel wäre also LongArray[0] das erste Array-Element, LongArray[1] das
zweite usw.
Diese Zählweise ist genau zu beachten. Das Array EinArray[3] enthält drei Elemente:
EinArray[0], EinArray[1] und EinArray[2]. Allgemein ausgedrückt, verfügt EinArray[n]
über n Elemente, die von EinArray[0] bis EinArray[n-1] durchnumeriert sind.
Die Elemente in LongArray[25] sind demnach von LongArray[0] bis LongArray[24] numeriert.
Listing 12.1 zeigt, wie man ein Array mit fünf Ganzzahlen deklariert und jedes
Element mit einem Wert füllt.
Listing 12.1: Ein Array für Integer-Zahlen
1: // Listing 12.1 - Arrays
2: #include <iostream.h>
3:
4: int main()
5: {
6: int myArray[5];
7: int i;
8: for (i=0; i<5; i++) // 0-4
9: {
10: cout << "Wert fuer myArray[" << i << "]: ";
11: cin >> myArray[i];
12: }
13: for (i = 0; i<5; i++)
14: cout << i << ": " << myArray[i] << "\n";
15: return 0;
16: }
Wert fuer myArray[0]: 3
Wert fuer myArray[1]: 6
Wert fuer myArray[2]: 9
Wert fuer myArray[3]: 12
Wert fuer myArray[4]: 15
0: 3
1: 6
2: 9
3: 12
4: 15
Zeile 6 deklariert das Array myArray, das fünf Integer-Variablen aufnimmt. Zeile 8 richtet
eine Schleife ein, die von 0 bis 4 zählt und damit genau die Indizes zum Durchlaufen
eines fünfelementigen Array erzeugt. Der Anwender gibt einen Wert ein, den das
Programm am richtigen Offset im Array speichert.
Der erste Wert kommt nach myArray[0], der zweite nach myArray[1] und so weiter.
Die zweite for-Schleife gibt alle Werte auf dem Bildschirm aus.
Die Indizierung von Arrays beginnt bei 0 und nicht bei 1. Hier liegt die Ursache für viele Fehler, die gerade Neueinsteigern in C++ unterlaufen. Man sollte immer daran denken, daß ein Array mit zehn Elementen von
ArrayName[0]bisArrayName[9]numeriert wird und es kein ElementArrayName[10]gibt.
Wenn Sie einen Wert in einem Array speichern, errechnet der Compiler anhand der
Größe der Elemente und dem angegebenen Index die Position im Array, an der der
Wert zu speichern ist. Angenommen, es ist ein Wert in LongArray[5] - also im sechsten
Element - einzutragen. Der Compiler multipliziert den Offset - 5 - mit der Größe
der Einzelelemente - in diesem Beispiel 4. Es ergibt sich eine Verschiebung (Offset)
von 20 Byte bezüglich des Array-Beginns. An diese Stelle schreibt das Programm den
Wert.
Wenn Sie in das Element LongArray[50] schreiben, ignoriert der Compiler die Tatsache,
daß es kein derartiges Element gibt, berechnet die Verschiebung zum ersten Element
- 200 Byte - und schreibt den Wert an diese Speicherstelle - ohne Rücksicht
darauf, was an dieser Speicherstelle bereits abgelegt ist. Dort können nahezu beliebige
Daten stehen, so daß das Überschreiben mit den neuen Daten zu unvorhersehbaren
Ergebnissen führen kann. Wenn man Glück hat, stürzt das Programm sofort ab. Andernfalls
erhält man wesentlich später im Programm seltsame Ergebnisse und kann
nur schwer herausfinden, was hier schiefgegangen ist.
Der Compiler verhält sich wie ein Blinder, der die Entfernung von seinem Haus abschreitet.
Er beginnt beim ersten Haus, Hauptstrasse[0]. Wenn man ihn bittet, zum
sechsten Haus in der Hauptstraße zu gehen, denkt er sich: »Ich muß noch weitere fünf
Häuser gehen. Jedes Haus ist vier große Schritte lang. Ich gehe also noch weitere 20
Schritte.« Bittet man ihn, zur Hauptstrasse[100] zu gehen, und die Hauptstraße hat
nur 25 Häuser, wird er 400 Schritte zurücklegen. Bevor er allerdings an seinem Ziel
ankommt, läuft er vielleicht in einen fahrenden Bus. Passen Sie also auf, wo Sie den
Mann hinschicken.
Listing 12.2 zeigt, was passiert, wenn Sie über das Ende eines Array hinausschreiben.
Führen Sie dieses Programm nicht aus. Es kann einen Systemabsturz auslösen!
Listing 12.2: Über das Ende eines Array schreiben
1: //Listing 12.2
2: // Demonstriert, was passiert, wenn Sie über das Ende
3: // eines Array hinausschreiben
4:
5: #include <iostream.h>
6: int main()
7: {
8: // Waechter
9: long sentinelOne[3];
10: long TargetArray[25]; // zu fuellendes Array
11: long sentinelTwo[3];
12: int i;
13: for (i=0; i<3; i++)
14: sentinelOne[i] = sentinelTwo[i] = 0;
15:
16: for (i=0; i<25; i++)
17: TargetArray[i] = 0;
18:
19: cout << "Test 1: \n"; // aktuelle Werte testen (sollten 0 sein)
20: cout << "TargetArray[0]: " << TargetArray[0] << "\n";
21: cout << "TargetArray[24]: " << TargetArray[24] << "\n\n";
22:
23: for (i = 0; i<3; i++)
24: {
25: cout << "sentinelOne[" << i << "]: ";
26: cout << sentinelOne[i] << "\n";
27: cout << "sentinelTwo[" << i << "]: ";
28: cout << sentinelTwo[i]<< "\n";
29: }
30:
31: cout << "\nZuweisen...";
32: for (i = 0; i<=25; i++)
33: TargetArray[i] = 20;
34:
35: cout << "\nTest 2: \n";
36: cout << "TargetArray[0]: " << TargetArray[0] << "\n";
37: cout << "TargetArray[24]: " << TargetArray[24] << "\n";
38: cout << "TargetArray[25]: " << TargetArray[25] << "\n\n";
39: for (i = 0; i<3; i++)
40: {
41: cout << "sentinelOne[" << i << "]: ";
42: cout << sentinelOne[i]<< "\n";
43: cout << "sentinelTwo[" << i << "]: ";
44: cout << sentinelTwo[i]<< "\n";
45: }
46:
47: return 0;
48: }
Test 1:
TargetArray[0]: 0
TargetArray[24]: 0
SentinelOne[0]: 0
SentinelTwo[0]: 0
SentinelOne[1]: 0
SentinelTwo[1]: 0
SentinelOne[2]: 0
SentinelTwo[2]: 0
Zuweisen...
Test 2:
TargetArray[0]: 20
TargetArray[24]: 20
TargetArray[25]: 20
SentinelOne[0]: 20
SentinelTwo[0]: 0
SentinelOne[1]: 0
SentinelTwo[1]: 0
SentinelOne[2]: 0
SentinelTwo[2]: 0
Die Zeilen 9 und 11 deklarieren zwei Arrays mit jeweils drei Integer, die als Sentinel
(Wächter) für TargetArray fungieren. Diese Sentinel-Arrays werden mit dem Wert 0
initialisiert. Wenn Speicherplatz über das Ende von TargetArray hinaus beschrieben
wird, sollten sich die Werte in den Sentinels ändern. Einige Compiler zählen dabei den
Speicher hoch, andere zählen runter. Aus diesem Grunde stehen die Sentinels zu beiden
Seiten von TargetArray.
In Test 1 werden die Sentinel-Werte zur Kontrolle ausgegeben (Zeilen 19 bis 29). Zeile
33 initialisiert alle Elemente von TargetArray mit 20, aber der Zähler zählt für TargetArray
bis zum Offset 25, der für TargetArray gar nicht existiert.
Die Zeilen 36 bis 38 geben als Teil von Test 2 einige Werte von TargetArray aus. Beachten
Sie, daß es TargetArray keine Probleme bereitet, den Wert 20 auszugeben.
Wenn jedoch SentinelOne und SentinelTwo ausgegeben werden, sieht man, daß sich
der Wert von SentinelOne geändert hat. Das liegt daran, daß der Speicherplatz, der
25 Elemente hinter TargetArray[0] liegt, von SentinelOne[0] eingenommen wird.
Mit dem Zugriff auf das nicht existierende Element TargetArray[25] wurde daher auf
SentinelOne[0] zugegriffen.
Dieser unangenehme Fehler ist ziemlich schwer zu finden, da der Wert von SentinelOne[0]
in einem Codeabschnitt geändert wurde, der überhaupt nicht in SentinelOne
schreibt.
Dieser Code verwendet »magische Zahlen«, wie 3 für die Größe des Sentinel-Array
und 25 für die Größe von TargetArray. Es ist sicherer, Konstanten zu verwenden, so
daß alle diese Werte an einer Stelle geändert werden können.
Beachten Sie, daß jeder Compiler Speicherplatz unterschiedlich verwendet. Deshalb können Ihre Ergebnisse von den hier gezeigten Werten abweichen.
Es kommt so häufig vor, daß man die Grenzen des Array um genau ein Element überschreitet, daß dieser Fehler sogar einen eigenen Namen bekommen hat: Fence Post Error, zu deutsch etwa »Zaunpfahlfehler«. Bei Denkspielen, in denen es um Schnelligkeit geht, begegnet man des öfteren der Frage, wie viele Zaunpfähle für einen Zaun von 10 Meter Länge erforderlich sind, wenn man einen Pfahl pro Meter benötigt. Die unüberlegte Antwort lautet oft 10, obwohl es natürlich 11 sind. Abbildung 12.2 verdeutlicht das.

Abbildung 12.2: Fence Post Errors
Gleichermaßen liegt man bei der intuitiven Indizierung des letzten Array-Elements meist daneben, und unzählige Programmierer haben sich darüber schon die Haare gerauft. Mit der Zeit geht es aber in Fleisch und Blut über, daß ein 25elementiges Array nur bis zum Element 24 numeriert ist, und daß man beim Zählen bei 0 beginnen muß. (Programmierer wundern sich oft, warum Häuser keine 0. Etage haben. In der Tat sind manche so schlau, die Taste 4 zu drücken, wenn sie in den fünften Stock möchten.)
Einige Programmierer bezeichnen
ArrayName[0]als das nullte Element. Diese Angewohnheit ist nicht zur Nachahmung zu empfehlen. WennArrayName[0]das nullte Element ist, was ist dannArrayName[1]? Das erste? Wenn ja, sind Sie dann noch imstande zu erkennen, daß sich hinterArrayName[24]nicht das 24ste, sondern das 25ste Element verbirgt? Wesentlich besser ist es zu sagen, daßArrayName[0]den Offset 0 hat und es sich um das erste Element handelt.
Einfache Arrays von vordefinierten Typen wie int-Zahlen oder Zeichen (char) kann
man bei der Deklaration direkt initialisieren. Dazu tippt man hinter den Array-Namen
ein Gleichheitszeichen und eine in geschweifte Klammern eingeschlossene Liste mit
den durch Komma getrennten Werten ein. Beispielsweise deklariert
int IntegerArray[5] = { 10, 20, 30, 40, 50 };
das Array IntegerArray mit fünf Ganzzahlen. Das Element IntegerArray[0] erhält
den Wert 10 zugewiesen, das Element IntegerArray[1] den Wert 20 und so weiter.
Wenn man die Größe des Array nicht angibt, wird ein Array erzeugt, das gerade groß genug ist, um die spezifizierten Initialisierungswerte aufzunehmen. Schreibt man beispielsweise
int IntegerArray[] = { 10, 20, 30, 40, 50 };
erzeugt man exakt das gleiche Array wie im vorherigen Beispiel.
Muß man die Größe des Array ermitteln, kann man den Compiler die Größe berechnen lassen. Zum Beispiel setzt
const USHORT IntegerArrayLength;
IntegerArrayLength = sizeof(IntegerArray)/sizeof(IntegerArray[0]);
die konstante USHORT-Variable IntegerArrayLength auf das Ergebnis, das man aus der
Division der Gesamtgröße des Array durch die Größe eines einzelnen Elements des
Array erhält. Der Quotient gibt die Anzahl der Elemente im Array an.
Die Initialisierungsliste darf nicht mehr Werte enthalten, als Elemente für das Array deklariert wurden. Die Anweisung
int IntegerArray[5] = { 10, 20, 30, 40, 50, 60};
führt zu einem Compiler-Fehler, da man ein fünfelementiges Array deklariert hat, aber sechs Werte initialisieren will. Dagegen ist die folgende Anweisung zulässig:
int IntegerArray[5] = { 10, 20};
Obwohl es keine Garantie dafür gibt, daß nichtinitialisierte Array-Elemente vom Compiler einen bestimmten Wert zugewiesen bekommen, werden Aggregate praktisch immer auf 0 gesetzt. Wenn man also ein Array-Element nicht initialisiert, erhält es automatisch den Wert 0.
Arrays können einen beliebigen Variablennamen haben, solange der Name noch
nicht von einer anderen Variablen oder einem anderen Array innerhalb des gleichen
Gültigkeitsbereichs besetzt ist. Deshalb ist es nicht erlaubt, gleichzeitig ein Array namens
meineKatzen[5] und eine Variable namens meineKatzen zu deklarieren.
Sie können die Array-Größe mit Konstanten oder mit einer Aufzählungskonstanten festlegen. Wie das geht, sehen Sie in Listing 12.3.
Listing 12.3: Konstanten und Aufzählungskonstanten zur Array-Indizierung
1: // Listing 12.3
2: // Arraygroessen mit Konstanten und Aufzählungskonstanten festlegen
3:
4: #include <iostream.h>
5: int main()
6: {
7: enum WeekDays { Sun, Mon, Tue,
8: Wed, Thu, Fri, Sat, DaysInWeek };
9: int ArrayWeek[DaysInWeek] = { 10, 20, 30, 40, 50, 60, 70 };
10:
11: cout << "Der Wert am Dienstag beträgt: " << ArrayWeek[Tue];
12: return 0;
13: }
Der Wert am Dienstag beträgt: 30
Zeile 7 definiert einen Aufzählungstyp namens WeekDays mit acht Elementen. Sunday
(Sonntag) entspricht dem Wert 0 und DaysInWeek (TageDerWoche) dem Wert 7.
Zeile 11 verwendet die Aufzählungskonstante Tue als Offset im Array. Da Tue als 2
ausgewertet wird, wird in Zeile 11 das dritte Element im Array, ArrayWeek[2], zurückgeliefert
und ausgegeben.
Die Deklaration eines Array setzt sich folgendermaßen zusammen: zuerst der Typ des zu speichernden Objekts, gefolgt von dem Namen des Array und einem Index, der angibt, wie viele Objekte in dem Array abgelegt werden.
int MeinIntegerArray[90];long * ArrayVonZeigernAufLongs[100];Für den Zugriff auf die Elemente im Array wird der Index-Operator eingesetzt.
int NeunterInteger = MeinIntegerArray[8];long * pLong = ArrayVonZeigernAufLongs[8];Die Zählung in den Arrays beginnt bei Null. Ein Array mit n Elementen, würde von 0 bis n-1 durchnumeriert.
Jedes Objekt - gleichgültig ob vordefiniert oder benutzerdefiniert - läßt sich in einem Array speichern. Wenn man das Array deklariert, teilt man dem Compiler den zu speichernden Typ und die Anzahl der Objekte mit, für die Platz zu reservieren ist. Der Compiler weiß anhand der Klassendeklaration, wieviel Speicher jedes Objekt belegt. Die Klasse muß über einen Standardkonstruktor ohne Argumente verfügen, damit sich die Objekte bei der Definition des Array erzeugen lassen.
Der Zugriff auf Datenelemente von Objekten, die in einem Array abgelegt sind, erfolgt
in zwei Schritten. Man identifiziert das Element des Array mit dem Index-Operator ([
]) und fügt dann den Elementoperator (.) an, um auf die gewünschte Elementvariable
zuzugreifen. Listing 12.4 demonstriert, wie man ein Array mit fünf CAT-Objekten erzeugt.
Listing 12.4: Ein Array von Objekten erzeugen
1: // Listing 12.4 - Ein Array von Objekten
2:
3: #include <iostream.h>
4:
5: class CAT
6: {
7: public:
8: CAT() { itsAge = 1; itsWeight=5; } // Standardkonstruktor
9: ~CAT() {} // Destruktor
10: int GetAge() const { return itsAge; }
11: int GetWeight() const { return itsWeight; }
12: void SetAge(int age) { itsAge = age; }
13:
14: private:
15: int itsAge;
16: int itsWeight;
17: };
18:
19: int main()
20: {
21: CAT Litter[5];
22: int i;
23: for (i = 0; i < 5; i++)
24: Litter[i].SetAge(2*i +1);
25:
26: for (i = 0; i < 5; i++)
27: {
28: cout << "Katze #" << i+1 << ": ";
29: cout << Litter[i].GetAge() << endl;
30: }
31: return 0;
32: }
Katze #1: 1
Katze #2: 3
Katze #3: 5
Katze #4: 7
Katze #5: 9
Die Zeilen 5 bis 17 deklarieren die Klasse CAT. Diese Klasse muß über einen Standardkonstruktor
verfügen, damit sich CAT-Objekte in einem Array erzeugen lassen. Denken
Sie daran, daß der Compiler keinen Standardkonstruktor bereitstellt, wenn man irgendeinen
anderen Konstruktor erzeugt - in diesem Fall müssen Sie einen eigenen
Standardkonstruktor erstellen.
Die erste for-Schleife (in den Zeilen 23 und 24) setzt das Alter aller fünf CAT-Objekte
im Array. Die zweite for-Schleife (in den Zeilen 26 bis 30) greift auf die einzelnen Elemente
des Arrays zu und ruft GetAge() für die Objekte auf.
Der Aufruf der GetAge()-Methode für die einzelnen CAT-Objekte erfolgt über den Namen
des Array-Elements Litter[i], gefolgt vom Punktoperator (.) und der Elementfunktion.
Arrays lassen sich in mehreren Dimensionen anlegen. Jede Dimension stellt man durch einen eigenen Index im Array dar. Ein zweidimensionales Array hat demzufolge zwei Indizes und ein dreidimensionales drei Indizes. Prinzipiell ist die Anzahl der Dimensionen nicht begrenzt, obwohl man in der Praxis kaum mit mehr als zwei Dimensionen arbeitet.
Ein Schachbrett liefert ein gutes Beispiel für ein zweidimensionales Array. Die acht Reihen sind der einen Dimension, die acht Spalten der anderen Dimension zugeordnet. Abbildung 12.3 verdeutlicht dies.
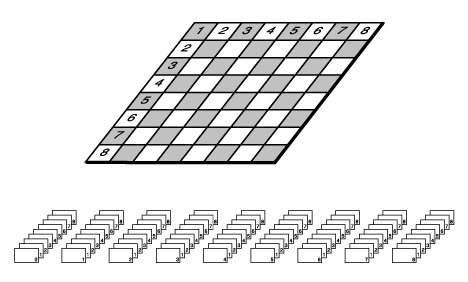
Abbildung 12.3: Ein Schachbrett und ein zweidimensionales Array
Nehmen Sie an, Sie hätten eine Klasse SQUARE für die Felder des Schachbretts. Ein Array
Brett zur Darstellung des Schachbretts deklariert man dann wie folgt:
SQUARE Brett[8][8];
Die gleichen Daten ließen sich auch in einem eindimensionalen Array für 64 Quadrate unterbringen:
SQUARE Brett[64];
Diese Darstellung lehnt sich allerdings nicht so eng an das reale Objekt an wie ein zweidimensionales Array. Bei Spielbeginn steht der König in der vierten Spalte der ersten Reihe. Da die Zählung bei 0 beginnt, entspricht diese Position
Brett[0][3];
- vorausgesetzt, daß der erste Index der Zeile und der zweite Index der Spalte zugeordnet ist. Die Anordnung aller Brettpositionen ist aus Abbildung 12.3 ersichtlich.
Um mehrdimensionale Arrays zu initialisieren, weist man den Array-Elementen die Liste der Werte der Reihe nach zu, wobei sich zuerst der letzte Index ändert, während die vorhergehenden Indizes konstant bleiben. Im Array
int dasArray[5][3];
kommen zum Beispiel die ersten drei Elemente nach dasArray[0], die nächsten drei
nach dasArray[1] usw.
Zur Initialisierung des Array schreibt man
int dasArray[5][3] = { 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15 };
Diese Anweisung läßt sich übersichtlicher darstellen, wenn man die einzelnen Initialisierungen mit geschweiften Klammern gruppiert:
int dasArray[5][3] = { {1,2,3},
{4,5,6},
{7,8,9},
{10,11,12},
{13,14,15} };
Die inneren geschweiften Klammern ignoriert der Compiler - sie dienen lediglich dem Programmierer zur übersichtlichen Gruppierung der Zahlen.
Die Werte sind durch Kommata zu trennen, unabhängig von eventuell vorhandenen Klammern. Die gesamte Initialisierungsliste ist in geschweifte Klammern einzuschließen und muß mit einem Semikolon enden.
Listing 12.5 erzeugt ein zweidimensionales Array.
Listing 12.5: Ein mehrdimensionales Array erzeugen
1: #include <iostream.h>
2: int main()
3: {
4: int SomeArray[5][2] = { {0,0}, {1,2}, {2,4}, {3,6}, {4,8}};
5: for (int i = 0; i<5; i++)
6: for (int j=0; j<2; j++)
7: {
8: cout << "SomeArray[" << i << "][" << j << "]: ";
9: cout << SomeArray[i][j]<< endl;
10: }
11:
12: return 0;
13: }
SomeArray[0][0]: 0
SomeArray[0][1]: 0
SomeArray[1][0]: 1
SomeArray[1][1]: 2
SomeArray[2][0]: 2
SomeArray[2][1]: 4
SomeArray[3][0]: 3
SomeArray[3][1]: 6
SomeArray[4][0]: 4
SomeArray[4][1]: 8
Zeile 4 deklariert SomeArray als zweidimensionales Array. Die erste Dimension besteht
aus fünf, die zweite Dimension aus zwei Ganzzahlen. Damit entsteht eine 5-mal-2-Matrix,
wie sie Abbildung 12.4 zeigt.
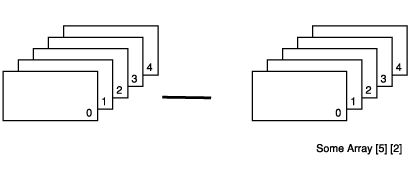
Abbildung 12.4: Eine 5-mal-2-Matrix
Die Initialisierung des Array erfolgt mit Wertepaaren, obwohl man die Werte genausogut
auch berechnen könnte. Die Zeilen 5 und 6 bilden eine verschachtelte for-Schleife.
Die äußere for-Schleife durchläuft alle Element der ersten Dimension. Für jedes
dieser Elemente durchläuft die innere for-Schleife alle Elemente der zweiten Dimension.
Dieser Ablauf dokumentiert sich in der Ausgabe: auf SomeArray[0][0] folgt SomeArray[0][1]
. Jeweils nach dem Inkrementieren der zweiten Dimension erhöht die
äußere for-Schleife den Index für die erste Dimension um 1. Dann beginnt die zweite
Dimension wieder von vorn (bei 0).
Bei der Deklaration eines Array teilt man dem Compiler die genaue Anzahl der im Array
zu speichernden Objekte mit. Der Compiler reserviert Speicher für alle Objekte,
auch wenn man sie überhaupt nicht verwendet. Bei Arrays, deren Größe von vornherein
in etwa bekannt ist, stellt das kein Problem dar. Beispielsweise hat ein Schachbrett
genau 64 Felder, und Katzen (CAT-Objekte) bekommen zwischen 1 und 10 Kätzchen.
Wenn man allerdings nur eine vage Vorstellung von der Anzahl der benötigten Objekte
hat, muß man auf ausgefeiltere Datenstrukturen ausweichen.
Die bisher behandelten Arrays speichern ihre Elemente auf dem Stack. Normalerweise
ist der Stack-Speicher stark begrenzt, während im Heap wesentlich mehr Platz zur
Verfügung steht. Man kann die Objekte aber auch im Heap anlegen und im Array nur
Zeiger auf die Objekte speichern. Damit reduziert sich die benötigte Stack-Größe drastisch.
Listing 12.6 ist eine Neuauflage von Listing 12.4, speichert aber nun alle Objekte
im Heap. Als Hinweis auf den jetzt möglichen größeren Speicher habe ich das
Array von 5 auf 500 Elemente erweitert und den Namen von Litter (Körbchen) in
Family (Familie) geändert.
Listing 12.6: Ein Array im Heap unterbringen
1: // Listing 12.6 - Ein Array von Zeigern auf Objekte
2:
3: #include <iostream.h>
4:
5: class CAT
6: {
7: public:
8: CAT() { itsAge = 1; itsWeight=5; } // Standardkonstruktor
9: ~CAT() {} // Destruktor
10: int GetAge() const { return itsAge; }
11: int GetWeight() const { return itsWeight; }
12: void SetAge(int age) { itsAge = age; }
13:
14: private:
15: int itsAge;
16: int itsWeight;
17: };
18:
19: int main()
20: {
21: CAT * Family[500];
22: int i;
23: CAT * pCat;
24: for (i = 0; i < 500; i++)
25: {
26: pCat = new CAT;
27: pCat->SetAge(2*i +1);
28: Family[i] = pCat;
29: }
30:
31: for (i = 0; i < 500; i++)
32: {
33: cout << "Katze #" << i+1 << ": ";
34: cout << Family[i]->GetAge() << endl;
35: }
36: return 0;
37: }
Katze #1: 1
Katze #2: 3
Katze #3: 5
...
Katze #499: 997
Katze #500: 999
Die in den Zeilen 5 bis 17 deklarierte CAT-Klasse ist mit der in Listing 12.4 deklarierten
CAT-Klasse identisch. Das in Zeile 21 deklarierte Array heißt jetzt aber Family und
ist für die Aufnahme von 500 Zeigern auf CAT-Objekte ausgelegt.
Die Initialisierungsschleife (in den Zeilen 24 bis 29) erzeugt 500 neue CAT-Objekte im
Heap und setzt die Werte für das Alter auf den zweifachen Indexwert plus 1. Das Alter
im ersten CAT-Objekt enthält demnach den Wert 1, das zweite den Wert 3, das dritte
den Wert 5 und so weiter. Schließlich legt die Initialisierungsschleife die Zeiger im Array
ab.
Da das Array für die Aufnahme von Zeigern deklariert ist, wird im Array der Zeiger - und nicht der dereferenzierte Wert des Zeigers - gespeichert.
Die zweite Schleife (Zeilen 31 bis 35) gibt alle Werte aus. Mit Hilfe des Index Family[i]
greift das Programm auf die Zeiger zu. Über die zurückgelieferte Adresse wird
die Methode GetAge() aufgerufen.
Dieses Beispiel speichert das Array Family und alle dazugehörenden Zeiger auf dem
Stack, während die 500 erzeugten CAT-Objekte im Heap abgelegt werden.
Man kann auch das gesamte Array auf dem Heap unterbringen. Dazu ruft man new
auf und verwendet den Index-Operator zur Angabe der Array-Größe. Das Ergebnis ist
ein Zeiger auf einen Bereich im Heap, der das Array enthält. Beispielsweise deklariert
CAT *Family = new CAT[500];
Family als Zeiger auf das erste Objekt in einem Array von 500 CAT-Objekten. Mit anderen
Worten zeigt Family auf das Element Family[0] bzw. enthält dessen Adresse.
Mittels Zeigerarithmetik kann man über Family auf jedes Element von Family zugreifen.
Beispielsweise kann man schreiben:
CAT *Family = new CAT[500];
CAT *pCat = Family; // pCat zeigt auf Family[0]
pCat->SetAge(10); // setzt Family[0] auf 10
pCat++; // geht weiter zu Family[1]
pCat->SetAge(20); // setzt Family[1] auf 20
Dieses Codefragment deklariert ein neues Array von 500 CAT-Objekten und einen Zeiger,
der auf den Beginn des Array verweist. Über diesen Zeiger ruft man die Funktion
SetAge() des ersten CAT-Objekts auf und übergibt den Wert 12. Die vierte Anweisung
inkrementiert den Zeiger, der danach auf das nächste CAT-Objekt verweist. Daran
schließt sich der Aufruf der SetAge()-Methode für das zweite CAT-Objekt an.
Sehen Sie sich die folgenden drei Deklarationen an:
1: CAT FamilyOne[500];
2: CAT * FamilyTwo[500];
3: CAT * FamilyThree = new CAT[500];
FamilyOne ist ein Array von 500 CAT-Objekten, FamilyTwo ein Array von 500 Zeigern
auf CAT-Objekte und FamilyThree ein Zeiger auf ein Array mit 500 CAT-Objekten.
Die Unterschiede zwischen den drei Codezeilen haben entscheidenden Einfluß auf die
Arbeitsweise der drei Arrays. Überraschend ist vielleicht, daß FamilyThree eine Variante
von FamilyOne ist, sich aber grundsätzlich von FamilyTwo unterscheidet.
Damit stellt sich die heikle Frage, wie sich Zeiger zu Arrays verhalten. Im dritten Fall
ist FamilyThree ein Zeiger auf ein Array. Das heißt, die Adresse in FamilyThree ist die
Adresse des ersten Elements in diesem Array. Genau das trifft auch auf FamilyOne zu.
In C++ ist ein Array-Name ein konstanter Zeiger auf das erste Element des Arrays. In der Deklaration
CAT Family[50];
ist Family demzufolge ein Zeiger auf das Element &Family[0] - also die Adresse des
ersten Array-Elements von Family.
Es ist zulässig, Array-Namen als konstante Zeiger - und konstante Zeiger als Array-
Namen - zu verwenden. Demzufolge kann man mit Family + 4 auf die Daten in Family[4]
zugreifen.
Der Compiler führt die korrekten Berechnungen aus, wenn man Zeiger addiert, inkrementiert
oder dekrementiert. Die Adresse für den Ausdruck Family + 4 liegt nämlich
nicht einfach 4 Byte, sondern 4 Objekte hinter der Adresse von Family. Hat jedes
Objekt eine Länge von 4 Byte, bedeutet Family + 4 eine Adreßverschiebung von
16 Byte. Handelt es sich zum Beispiel um CAT-Objekte mit vier Elementvariablen vom
Typ long (jeweils 4 Byte) und zwei Elementvariablen vom Typ short (jeweils 2 Byte),
dann beträgt die Länge eines CAT-Objekts 20 Byte und Family + 4 liegt 80 Byte hinter
dem Array-Anfang.
Listing 12.7 zeigt die Deklaration und Verwendung eines Arrays auf dem Heap.
Listing 12.7: Ein Array mit new erzeugen
1: // Listing 12.7 - Ein Array auf dem Heap
2:
3: #include <iostream.h>
4:
5: class CAT
6: {
7: public:
8: CAT() { itsAge = 1; itsWeight=5; }
9: ~CAT();
10: int GetAge() const { return itsAge; }
11: int GetWeight() const { return itsWeight; }
12: void SetAge(int age) { itsAge = age; }
13:
14: private:
15: int itsAge;
16: int itsWeight;
17: };
18:
19: CAT :: ~CAT()
20: {
21: // cout << "Destruktor aufgerufen!\n";
22: }
23:
24: int main()
25: {
26: CAT * Family = new CAT[500];
27: int i;
28:
29: for (i = 0; i < 500; i++)
30: {
31: Family[i].SetAge(2*1 +1);
32: }
33:
34: for (i = 0; i < 500; i++)
35: {
36: cout << "Katze #" << i+1 << ": ";
37: cout << Family[i].GetAge() << endl;
38: }
39:
40: delete [] Family;
41:
42: return 0;
43: }
Katze #1: 1
Katze #2: 3
Katze #3: 5
...
Katze #499: 997
Katze #500: 999
Zeile 26 deklariert das Array Family für 500 CAT-Objekte. Der Aufruf new CAT[500] erzeugt
das gesamte Array auf dem Heap.
Was passiert mit dem Speicher, der den CAT-Objekten aus obigem Beispiel zugewiesen
wurde, wenn das Array zerstört wird? Besteht die Gefahr eines Speicherlecks? Beim
Löschen von Family wird automatisch der gesamte Speicherplatz, der für das Array
reserviert wurde, zurückgegeben, wenn Sie den delete[]-Operator auf das Array anwenden
und nicht die eckigen Klammern vergessen. Der Compiler ist intelligent genug,
um alle Objekte im Array zu zerstören und dessen Speicher an den Heap zurückzugeben.
Um sich selbst davon zu überzeugen, ändern Sie die Größe des Arrays in den Zeilen
26, 29 und 34 von 500 auf 12. Entfernen Sie außerdem die Kommentarzeichen vor
der cout-Anweisung in Zeile 21. Erreicht das Programm Zeile 43 und zerstört das Array,
wird der Destruktor für jedes CAT-Objekt aufgerufen.
Wenn man mit new ein einzelnes Element auf dem Heap erzeugt, ruft man zum Löschen
des Elements und zur Freigabe des zugehörigen Speichers immer den delete-
Operator auf. Wenn man ein Array mit new <class>[size] erzeugt, schreibt man delete[]
, um dieses Array zu löschen und dessen Speicher freizugeben. Die eckigen
Klammern signalisieren dem Compiler, daß ein Array zu löschen ist.
Wenn man die Klammern wegläßt, wird nur das erste Objekt im Array gelöscht. Sie
können das selbst nachprüfen, indem Sie die eckigen Klammern in Zeile 38 entfernen.
Zeile 21 sollte auch hier keine Kommentarzeichen enthalten, damit sich der Destruktor
meldet. Beim Programmlauf stellen Sie dann fest, daß nur ein einziges CAT-
Objekt zerstört wird. Herzlichen Glückwunsch! Gerade haben Sie eine Speicherlücke
erzeugt.
Ein String ist eine Folge einzelner Zeichen. Die bisher gezeigten Strings waren ausnahmslos
unbenannte String-Konstanten in cout-Anweisungen wie zum Beispiel
cout << "hello world.\n";
Ein String in C++ ist ein Array mit Elementen vom Typ char und einem Null-Zeichen
zum Abschluß. Man kann einen String genauso deklarieren und initialisieren wie jedes
andere Array. Dazu folgendes Beispiel:
char Gruss[] = { 'H', 'e', 'l', 'l', 'o', ' ', 'W','o','r','l','d', '\0' };
Das letzte Zeichen, '\0', ist das Null-Zeichen, das viele Funktionen in C++ als Abschlußzeichen
eines Strings erkennen. Obwohl diese zeichenweise Lösung funktioniert,
ist sie umständlich einzugeben und bietet viel Spielraum für Fehler. C++ erlaubt
daher die Verwendung einer Kurzform für die obige Codezeile:
char Gruss[] = "Hello World";
Bei dieser Syntax sind zwei Punkte zu beachten:
Der String Hello World hat eine Länge von 12 Byte: Hello mit 5 Byte, ein Leerzeichen
mit 1 Byte, World mit 5 Byte und das abschließende Null-Zeichen mit 1 Byte.
Man kann auch nicht initialisierte Zeichen-Arrays erzeugen. Wie bei allen Arrays darf man nur so viele Zeichen in den Puffer stellen, wie Platz dafür reserviert ist.
Listing 12.8 zeigt die Verwendung eines nicht initialisierten Puffers.
Listing 12.8: Ein Array füllen
1: // Listing 12.8 Puffer für Zeichen-Array
2:
3: #include <iostream.h>
4:
5: int main()
6: {
7: char buffer[80];
8: cout << "Geben Sie den String ein: ";
9: cin >> buffer;
10: cout << "Inhalt des Puffers: " << buffer << endl;
11: return 0;
12: }
Geben Sie den String ein: Hello World
Inhalt des Puffers: Hello
Zeile 7 deklariert einen Puffer für 80 Zeichen. Diese Größe genügt, um eine Zeichenfolge mit 79 Zeichen und dem abschließenden Null-Zeichen aufzunehmen.
Die Anweisung in Zeile 8 fordert den Anwender zur Eingabe einer Zeichenfolge auf,
die das Programm in Zeile 9 in den Puffer übernimmt. cin schreibt nach der eingegebenen
Zeichenfolge ein abschließendes Null-Zeichen in den Puffer.
Das Programm in Listing 12.8 weist zwei Probleme auf. Erstens: Wenn der Anwender
mehr als 79 Zeichen eingibt, schreibt cin über das Ende des Puffers hinaus. Zweitens:
Wenn der Anwender ein Leerzeichen eingibt, nimmt cin das Ende des Strings an und
beendet die Eingabe in den Puffer.
Um diese Probleme zu lösen, muß man die cin-Methode get() aufrufen, die drei Parameter
übernimmt:
Der Standardbegrenzer ist newline (Zeichen für neue Zeile). Listing 12.9 zeigt dazu
ein Beispiel.
Listing 12.9: Ein Array füllen
1: // Listing 12.9 Arbeiten mit cin.get()
2:
3: #include <iostream.h>
4:
5: int main()
6: {
7: char buffer[80];
8: cout << "Geben Sie den String ein: ";
9: cin.get(buffer, 79); // Maximal 79 Zeichen oder bis newline einlesen
10: cout << "Inhalt des Puffers: " << buffer << endl;
11: return 0;
12: }
Geben Sie den String ein: Hello World
Inhalt des Puffers: Hello World
Zeile 9 ruft die Methode get() von cin auf und übergibt den in Zeile 7 deklarierten
Puffer als erstes Argument. Das zweite Argument gibt die maximal zu holenden Zeichen
an. In diesem Fall muß dieser Wert gleich 79 sein, um Platz für das abschließende
Null-Zeichen zu lassen. Auf die Angabe eines Zeichens für das Ende der Eingabe
kann man verzichten, da der Standardwert newline unseren Ansprüchen genügt.
C++ erbt von C eine Funktionsbibliothek für die Behandlung von Strings. Unter den
zahlreichen Funktionen finden sich zwei für das Kopieren eines Strings in einen anderen:
strcpy() und strncpy(). Die Funktion strcpy() kopiert den gesamten Inhalt eines
Strings in den angegebenen Puffer. Listing 12.10 zeigt hierfür ein Beispiel.
Listing 12.10: Die Funktion strcpy()
1: #include <iostream.h>
2: #include <string.h>
3: int main()
4: {
5: char String1[] = "Keiner lebt fuer sich allein.";
6: char String2[80];
7:
8: strcpy(String2,String1);
9:
10: cout << "String1: " << String1 << endl;
11: cout << "String2: " << String2 << endl;
12: return 0;
13: }
String1: Keiner lebt fuer sich allein.
String2: Keiner lebt fuer sich allein.
Zeile 2 bindet die Header-Datei STRING.H ein. Diese Datei enthält den Prototyp der
Funktion strcpy(). Als Parameter übernimmt die Funktion strcpy() zwei Zeichen-Arrays
- ein Ziel und anschließend eine Quelle. Wenn die Quelle größer als das Ziel ist,
schreibt strcpy() über das Ende des Puffers hinaus.
Mit der Funktion strncpy() aus der Standardbibliothek kann man sich dagegen schützen.
Diese Version übernimmt die Maximalzahl der zu kopierenden Zeichen. Die
Funktion strncpy() kopiert bis zum ersten Null-Zeichen oder bis zu der als Argument
übergebenen Maximalzahl von Zeichen in den Zielpuffer.
Listing 12.11 zeigt die Verwendung von strncpy().
Listing 12.11: Die Funktion strncpy()
1: #include <iostream.h>
2: #include <string.h>
3: int main()
4: {
5: const int MaxLength = 80;
6: char String1[] = "Keiner lebt fuer sich allein.";
7: char String2[MaxLength+1];
8:
9:
10: strncpy(String2,String1,MaxLength);
11:
12: cout << "String1: " << String1 << endl;
13: cout << "String2: " << String2 << endl;
14: return 0;
15: }
String1: Keiner lebt fuer sich allein.
String2: Keiner lebt fuer sich allein.
In Zeile 10 wurde der Aufruf von strcpy() in strncpy() geändert. Hinzugekommen ist
im Aufruf ein dritter Parameter: die maximale Anzahl der zu kopierenden Zeichen.
Der Puffer String2 ist für die Aufnahme von MaxLength+1 Zeichen deklariert. Der zusätzliche
Platz ist für das Null-Zeichen reserviert, das sowohl strcpy() als auch strncpy()
automatisch an das Ende des Strings anfügt.
Zu den meisten C++-Compilern gehört eine umfangreiche Bibliothek mit Klassen für
die Manipulation von Daten. Zu den Standardkomponenten dieser Bibliotheken gehört
auch eine String-Klasse.
C++ hat zwar den Null-terminierten String und die Funktionsbibliothek mit der Funktion
strcpy() von C geerbt, allerdings fügen sich diese Funktionen nicht in das objektorientierte
Konzept ein. Eine String-Klasse stellt einen abgekapselten Satz von Daten
und Funktionen für die Manipulation dieser Daten sowie Zugriffsfunktionen bereit, so
daß die Daten selbst gegenüber den Klienten der String-Klasse verborgen sind.
Wenn zu Ihrem Compiler noch keine String-Klasse gehört (oder deren Implementierung
unbefriedigend ist), sollten Sie sich eine eigene zusammenbauen. Im Anschluß an
diesen Abschnitt werden der Entwurf und die teilweise Implementierung von String-
Klassen diskutiert.
Das mindeste, was eine String-Klasse leisten sollte, ist, die grundlegenden Beschränkungen
von Zeichen-Arrays aufzuheben. Wie alle Arrays sind auch Zeichen-Arrays
statisch. Damit ist ihre Größe von vornherein festgelegt, und sie belegen immer den
gleichen Platz im Speicher, auch wenn man ihn überhaupt nicht nutzt. Das Schreiben
über das Ende des Array hinaus hat verheerende Folgen.
Eine gute String-Klasse reserviert nur soviel Speicher wie nötig. Kann die Klasse nicht
genügend Speicher für einen aufzunehmenden String reservieren, sollte die Klasse
darauf in angemessener Weise reagieren.
Listing 12.12 zeigt eine erste Annäherung an eine String-Klasse.
Listing 12.12: Verwendung einer String-Klasse
1: //Listing 12.12
2:
3: #include <iostream.h>
4: #include <string.h>
5:
6: // Rudimentaere String-Klasse
7: class String
8: {
9: public:
10: // Konstruktoren
11: String();
12: String(const char *const);
13: String(const String &);
14: ~String();
15:
16: // Ueberladene Operatoren
17: char & operator[](unsigned short offset);
18: char operator[](unsigned short offset) const;
19: String operator+(const String&);
20: void operator+=(const String&);
21: String & operator= (const String &);
22:
23: // Allgemeine Zugriffsfunktionen
24: unsigned short GetLen()const { return itsLen; }
25: const char * GetString() const { return itsString; }
26:
27: private:
28: String (unsigned short); // privater Konstruktor
29: char * itsString;
30: unsigned short itsLen;
31: };
32:
33: // Standardkonstruktor erzeugt einen String von 0 Byte
34: String::String()
35: {
36: itsString = new char[1];
37: itsString[0] = '\0';
38: itsLen=0;
39: }
40:
41: // privater (Hilfs-)Konstruktor, wird nur von
42: // Klassenmethoden verwendet, um einen neuen Null-String
43: // von erforderlicher Groesse zu erzeugen.
44: String::String(unsigned short len)
45: {
46: itsString = new char[len+1];
47: for (unsigned short i = 0; i<=len; i++)
48: itsString[i] = '\0';
49: itsLen=len;
50: }
51:
52: // Konvertiert ein Zeichenarray in einen String
53: String::String(const char * const cString)
54: {
55: itsLen = strlen(cString);
56: itsString = new char[itsLen+1];
57: for (unsigned short i = 0; i<itsLen; i++)
58: itsString[i] = cString[i];
59: itsString[itsLen]='\0';
60: }
61:
62: // Kopierkonstruktor
63: String::String (const String & rhs)
64: {
65: itsLen=rhs.GetLen();
66: itsString = new char[itsLen+1];
67: for (unsigned short i = 0; i<itsLen;i++)
68: itsString[i] = rhs[i];
69: itsString[itsLen] = '\0';
70: }
71:
72: // Destruktor, gibt zugewiesenen Speicher frei
73: String::~String ()
74: {
75: delete [] itsString;
76: itsLen = 0;
77: }
78:
79: // Selbstzuweisung pruefen, Speicher freigeben,
80: // dann String und Groesse kopieren
81: String& String::operator=(const String & rhs)
82: {
83: if (this == &rhs)
84: return *this;
85: delete [] itsString;
86: itsLen=rhs.GetLen();
87: itsString = new char[itsLen+1];
88: for (unsigned short i = 0; i<itsLen;i++)
89: itsString[i] = rhs[i];
90: itsString[itsLen] = '\0';
91: return *this;
92: }
93:
94: // Nicht-konstanter Offset-Operator, gibt
95: // Referenz auf Zeichen zurueck, so dass es
96: // geaendert werden kann!
97: char & String::operator[](unsigned short offset)
98: {
99: if (offset > itsLen)
100: return itsString[itsLen-1];
101: else
102: return itsString[offset];
103: }
104:
105: // konstanter Offset-Operator für konstante
106: // Objekte (siehe Kopierkonstruktor!)
107: char String::operator[](unsigned short offset) const
108: {
109: if (offset > itsLen)
110: return itsString[itsLen-1];
111: else
112: return itsString[offset];
113: }
114:
115: // erzeugt einen neuen String, indem er rhs den
116: // aktuellen String hinzufügt
117: String String::operator+(const String& rhs)
118: {
119: unsigned short totalLen = itsLen + rhs.GetLen();
120: String temp(totalLen);
121: unsigned short i;
122: for ( i= 0; i<itsLen; i++)
123: temp[i] = itsString[i];
124: for (unsigned short j = 0; j<rhs.GetLen(); j++, i++)
125: temp[i] = rhs[j];
126: temp[totalLen]='\0';
127: return temp;
128: }
129:
130: // aendert aktuellen String, gibt nichts zurueck
131: void String::operator+=(const String& rhs)
132: {
133: unsigned short rhsLen = rhs.GetLen();
134: unsigned short totalLen = itsLen + rhsLen;
135: String temp(totalLen);
136: unsigned short i;
137: for (i = 0; i<itsLen; i++)
138: temp[i] = itsString[i];
139: for (unsigned short j = 0; j<rhs.GetLen(); j++, i++)
140: temp[i] = rhs[i-itsLen];
141: temp[totalLen]='\0';
142: *this = temp;
143: }
144:
145: int main()
146: {
147: String s1("Erster Test");
148: cout << "S1:\t" << s1.GetString() << endl;
149:
150: char * temp = "Hello World";
151: s1 = temp;
152: cout << "S1:\t" << s1.GetString() << endl;
153:
154: char tempTwo[20];
155: strcpy(tempTwo,"; schoen hier zu sein!");
156: s1 += tempTwo;
157: cout << "tempTwo:\t" << tempTwo << endl;
158: cout << "S1:\t" << s1.GetString() << endl;
159:
160: cout << "S1[4]:\t" << s1[4] << endl;
161: s1[4]='x';
162: cout << "S1:\t" << s1.GetString() << endl;
163:
164: cout << "S1[999]:\t" << s1[999] << endl;
165:
166: String s2(" Ein anderer String");
167: String s3;
168: s3 = s1+s2;
169: cout << "S3:\t" << s3.GetString() << endl;
170:
171: String s4;
172: s4 = "Warum funktioniert dies?";
173: cout << "S4:\t" << s4.GetString() << endl;
174: return 0;
175: }
S1: initial test
S1: Hello world
tempTwo: ; schoen hier zu sein!
S1: Hello world; schoen hier zu sein!
S1[4]: o
S1: Hello World; schoen hier zu sein!
S1[999]: !
S3: Hello World; schoen hier zu sein! Ein anderer String
S4: Warum funktioniert dies?
Die Zeilen 7 bis 31 enthalten die Deklaration einer einfachen String-Klasse. Die Zeilen
11 bis 13 deklarieren drei Konstruktoren: den Standardkonstruktor, den Kopierkonstruktor
und einen Konstruktor, der einen existierenden, Null-terminierten String
(C-Stil) übernimmt.
Unsere String-Klasse überlädt den Offset-Operator ([]), den Plus-Operator (+) und
den Plus-Gleich-Operator(+=). Der Offset-Operator wird zweimal überladen: einmal als
konstante Funktion, die ein char zurückliefert, und einmal als nicht-konstante Funktion,
die eine Referenz auf einen char zurückliefert.
Die nicht-konstante Version wird in Anweisungen wie
SomeString[4]='x';
in Zeile 161 verwendet. Damit wird der direkte Zugriff auf jedes der Zeichen im String möglich. Es wird eine Referenz auf das Zeichen zurückgeliefert, so daß die aufrufende Funktion dieses manipulieren kann.
Die konstante Funktion wird eingesetzt, wenn auf ein konstantes String-Objekt zugegriffen
wird, wie zum Beispiel bei der Implementierung des Kopierkonstruktors (Zeile
63). Beachten Sie, daß der Zugriff auf rhs[i] erfolgt, aber rhs als const String & deklariert
ist. Es ist nicht zulässig, auf dieses Objekt mit einer nicht-konstanten Elementfunktion
zuzugreifen. Deshalb muß der Offset-Operator für den konstanten Zugiff
überladen werden.
Ist das zurückgegebene Objekt groß, wollen Sie vielleicht den Rückgabewert als konstante
Referenz deklarieren. Da char jedoch nur ein Byte groß ist, besteht dafür kein
Anlaß.
Die Zeilen 33 bis 39 implementieren den Standardkonstruktor. Er erzeugt einen
String der Länge 0. In unserer String-Klasse gilt die Regel, daß bei Angabe der Länge
des Strings das abschließende Null-Zeichen nicht mitgezählt wird. Der Standardstring
enthält lediglich das Null-Zeichen.
Die Zeilen 63 bis 70 implementieren den Kopierkonstruktor. Er setzt die Länge des neuen Strings auf die Länge des existierenden Strings plus 1 für das abschließende Null-Zeichen. Er kopiert jedes Zeichen des existierenden Strings in den neuen String, der dann mit dem Null-Zeichen abgeschlossen wird.
Die Zeilen 53 bis 60 implementieren den Konstruktor, der einen existierenden C-Stil-
String übernimmt. Dieser Konstruktor ist dem Kopierkonstruktor ähnlich. Die Länge
des existierenden Strings wird durch einen Aufruf der Standardfunktion strlen() aus
der String-Bibliothek eingerichtet.
Zeile 28 deklariert einen weiteren Konstruktor, String(unsigned short), als private
Elementfunktion. Die private-Deklaration soll sicherstellen, daß keine Client-Klasse je
einen String von beliebiger Länge erzeugt. Dieser Konstruktor dient lediglich dazu, die
interne Erzeugung von Strings zu unterstützen, wie sie zum Beispiel vom +=-Operator
in Zeile 131 benötigt werden. Doch darauf werden wir später im Zusammenhang mit
dem +=-Operator noch näher eingehen.
Der Konstruktor String(unsigned short) füllt jedes Element seines Array mit dem
Null-Zeichen. Deshalb testet die for-Schleife auf i<=len und nicht auf i<len.
Der in den Zeilen 73 bis 77 implementierte Destruktor löscht den Zeichenstring, der
von der Klasse verwaltet wird. Vergessen Sie nicht die eckigen Klammern mit in den
Aufruf des delete-Operators aufzunehmen, so daß jedes Element des Array und nicht
nur das erste Element gelöscht wird.
Der Zuweisungsoperator prüft zuerst, ob die rechte Seite der Zuweisung mit der linken identisch ist. Wenn nicht, wird der aktuelle String gelöscht, der neue String wird erzeugt und der übergebene String kopiert. Mit einer Referenz als Rückgabewert ermöglicht man Zuweisungen wie
String1 = String2 = String3;
Der Offset-Operator wird zweimal überladen. In beiden Versionen wird eine rudimentäre
Begrenzungsprüfung ausgeführt. Wenn der Benutzer versucht, auf ein Zeichen an
einer Position hinter dem Array-Ende zuzugreifen, wird das letzte Zeichen - das heißt
len-1 - zurückgeliefert.
Die Zeilen 117 bis 128 implementieren den Plus-Operator (+) als Verkettungsoperator.
Dies ermöglicht die bequeme Aneinanderreihung von Strings:
String3 = String1 + String2;
Um dies zu erreichen, berechnet die Operatorfunktion die Gesamtlänge der beiden
String-Operanden und erzeugt den temporären String temp. Dazu wird der private
Konstruktor aufgerufen, der einen Integer übernimmt und einen mit Null-Zeichen gefüllten
String erzeugt. Die Null-Zeichen werden dann durch den Inhalt der beiden
Strings ersetzt. Zuerst wird der linke String (*this) kopiert und anschließend der rechte
String (rhs).
Die erste for-Schleife durchläuft den linken String und schreibt die einzelnen Zeichen
in den neuen String. Die zweite for-Schleife durchläuft den rechten String. Beachten
Sie, daß i auch in der for-Schleife für den rhs-String weiter inkrementiert wird, um
die Einfügeposition in den neuen String vorzurücken.
Der Plus-Operator liefert den temp-String als Wert zurück, der dem String links des Zuweisungsoperators
(string1) zugewiesen werden kann. Der +=-Operator operiert auf
dem bestehenden String auf der linken Seite der Anweisung string1 += string2. Er
funktioniert genauso wie der +-Operator, mit der Ausnahme, daß der temp-Wert dem
aktuellen String (*this = temp) zugewiesen wird (Zeile 142).
Die main()-Funktion (Zeile 145 bis 175) fungiert als Testrahmen für die String-Klasse.
Zeile 147 erzeugt ein String-Objekt unter Verwendung des Konstruktors, der einen
C-Stil-String mit abschließendem Null-Zeichen übernimmt. Zeile 148 gibt dessen Inhalt
mit Hilfe der Zugriffsmethode GetString() aus. Zeile 150 erzeugt einen weiteren
C-Stil-String. Zeile 151 testet den Zuweisungsoperator und Zeile 152 gibt die Ergebnisse
aus.
Zeile 154 erzeugt einen dritten C-Stil-String, tempTwo. Zeile 155 ruft strcpy() auf, um
den Puffer mit den Zeichen ; schön hier zu sein! aufzufüllen. Zeile 156 ruft den +=-
Operator auf und verknüpft tempTwo mit dem bestehenden String s1. Zeile 158 gibt
das Ergebnis aus.
In Zeile 160 wird das fünfte Zeichen in s1 ausgegeben. In Zeile 161 wird dem Zeichen
ein neuer Wert zugewiesen. Damit wird der nicht-konstante Offset-Operator ([]) aufgerufen.
Zeile 162 zeigt das Ergebnis, aus dem ersichtlich wird, daß sich der Wert tatsächlich
geändert hat.
Zeile 164 versucht, auf ein Zeichen hinter dem Ende des Array zuzugreifen. Es wird, wie es der Entwurf vorsieht, das letzte Zeichen des Array zurückgeliefert.
Die Zeilen 166 und 167 erzeugen zwei weitere String-Objekte, und Zeile 168 ruft
den Additionsoperator auf. Das Ergebnis wird in Zeile 169 ausgegeben.
Zeile 171 erzeugt das neues String-Objekt s4. Zeile 172 ruft den Zuweisungsoperator
auf. Zeile 173 gibt das Ergebnis aus. Vielleicht fragen Sie sich, warum es zulässig ist,
daß der Zuweisungsoperator, dessen Definition in Zeile 21 die Übernahme einer konstanten
String-Referenz vorsieht, hier vom Programm einen C-Stil-String übernimmt.
Die Antwort lautet, daß der Compiler ein String-Objekt erwartet, aber ein Zeichen-
Array erhält. Deshalb prüft er, ob er aus dem, was ihm gegeben wurde, ein String-
Objekt erzeugen kann. In Zeile 12 haben Sie einen Konstruktor deklariert, der String-
Objekte aus Zeichen-Arrays erzeugten. Der Compiler erzeugt ein temporäres String-
Objekt aus dem Zeichen-Array und übergibt es dem Zuweisungsoperator. Dies wird
auch als implizite Typumwandlung oder Promotion bezeichnet. Hätten Sie keinen
Konstruktor definiert, der ein Zeichen-Array übernimmt, hätte diese Zuweisung einen
Kompilierfehler zur Folge gehabt.
Arrays lassen sich in vielerlei Hinsicht mit Tupperware vergleichen. Es sind hervorragende Behälter, sie besitzen aber eine feste Größe. Wählt man einen zu großen Behälter, verschwendet man Platz im Kühlschrank. Nimmt man einen zu kleinen Behälter, quillt der Inhalt über.
Zur Lösung dieses Problems bietet sich eine verkettete Liste an. Dabei handelt es sich
um eine Datenstruktur aus kleinen Behältern, die aneinander»gekoppelt« werden. Der
Grundgedanke besteht darin, eine Klasse zu schreiben, die genau ein Objekt der Daten
enthält - etwa ein CAT- oder ein Rectangle-Objekt - und auf den nächsten Behälter
in der Liste zeigen kann. Dann erzeugt man einen Behälter für jedes zu speichernde
Objekt und verkettet die Behälter.
Die Behälter heißen Knoten. Den ersten Knoten in der Liste bezeichnet man als Kopf.
Man unterscheidet bei Listen drei grundlegende Formen. Von der einfachsten zur komplexesten sind das
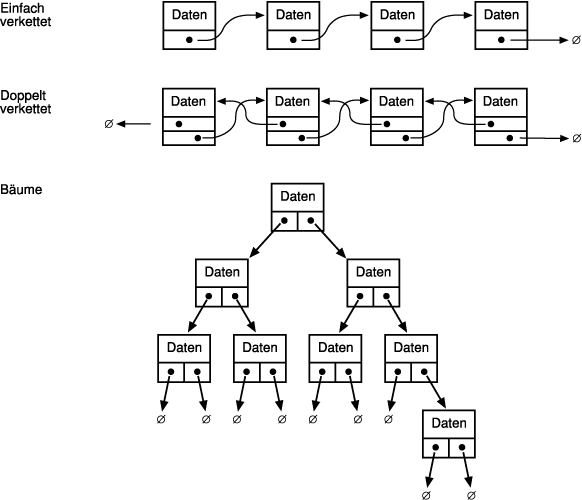
In einer einfach verketteten Liste zeigt jeder Knoten auf den nächsten, jedoch nicht auf den vorhergehenden. Um einen bestimmten Knoten zu finden, beginnt man am Anfang der Liste und tastet sich wie bei einer Schnitzeljagd (»der nächste Knoten liegt unter dem Sofa«) von Knoten zu Knoten. Eine doppelt verkettete Liste kann man sowohl in Vorwärts- als auch in Rückwärtsrichtung durchlaufen. Ein Baum ist eine komplexe Struktur, die sich aus Knoten aufbaut. Jeder Knoten kann in zwei oder drei Richtungen zeigen. Abbildung 12.5 zeigt diese drei fundamentalen Strukturen.
In diesem Abschnitt untersuchen wir anhand einer Fallstudie zum Aufbau einer verketteten Liste, wie man komplexe Strukturen erzeugt und wie man große Projekte mit Vererbung, Polymorphie und Kapselung verwaltet.
Eine grundlegende Prämisse der objektorientierten Programmierung besteht darin, daß jedes Objekt genau eine Aufgabe erledigt und alles, was nicht zu seinem »Kerngeschäft« gehört, an andere Objekte delegiert.
Ein Auto ist ein gutes Beispiel für dieses Konzept: Die Aufgabe des Motors besteht in der Leistungserzeugung. Die Verteilung dieser Leistung gehört nicht zu den Aufgaben des Motors, sondern kommt den Einrichtungen der Kraftübertragung zu. Weder die Rollbewegung noch die Kraftübertragung gehören zum Job des Motors, diese Aufgabe wird an die Räder weitergereicht.
Eine gut konzipierte Maschine besteht aus einer Menge kleiner Teile mit genau umrissenen Aufgaben, die in ihrer Gesamtheit die vorgesehene Funktionalität realisieren. Das gleiche gilt für ein gut konzipiertes Programm: jede Klasse arbeitet still vor sich hin, zusammengenommen bilden sie die eierlegende Wollmilchsau.
Die verkettete Liste besteht aus Knoten. Die Knotenklasse selbst ist abstrakt, die eigentliche Arbeit wird in drei Untertypen geleistet. Es gibt einen Kopfknoten, der den Kopf der Liste verwaltet, einen Endknoten und Null oder mehrere interne Knoten. Die internen Knoten verwahren die eigentlich in die Liste aufzunehmenden Daten.
Beachten Sie, daß die Daten und die Liste zwei verschiedene Paar Schuhe sind. Man kann theoretisch jeden beliebigen Datentyp in einer Liste speichern. Nicht die Daten sind verkettet, sondern die Knoten, die die Daten aufnehmen.
Das Rahmenprogramm bekommt von den Knoten nichts mit. Es arbeitet mit der Liste. Die Liste führt allerdings kaum Aufgaben aus, sondern delegiert sie einfach an die Knoten.
Listing 12.13 zeigt den Code, den wir eingehend untersuchen werden.
Listing 12.13: Eine verkettete Liste
0: // ***********************************************
1: // Datei: Listing 12.13
2: //
3: // Zweck: Demonstriert verkettete Liste
4: // Hinweise:
5: //
6: // COPYRIGHT: Copyright (C) 1997 Liberty Associates, Inc.
7: // All Rights Reserved
8: //
9: // Zeigt objektorientierte Loesung fuer verkettete Listen.
10: // Die Liste delegiert die eigentliche Arbeit an die
11: // Knoten. Die Knoten sind abstrakte Datentypen. Es gibt
12: // drei Knotentypen: Kopfknoten, Endknoten und interne
13: // Knoten. Nur die internen Knoten nehmen Daten auf.
14: //
15: // Die Klasse Data dient als Objekt, das in der
16: // verketteten Liste gespeichert wird.
17: //
18: // ***********************************************
19:
20:
21: #include <iostream.h>
22:
23: enum { kIsSmaller, kIsLarger, kIsSame};
24:
25: // Data-Klasse für die Speicherung in der Liste
26: // Jede Klasse in dieser Liste muss zwei Methoden unterstuetzen:
27: // Show (zeigt den Wert an) und Compare (gibt relative Position zurück)
28: class Data
29: {
30: public:
31: Data(int val):myValue(val){}
32: ~Data(){}
33: int Compare(const Data &);
34: void Show() { cout << myValue << endl; }
35: private:
36: int myValue;
37: };
38:
39: // Compare entscheidet, wohin ein bestimmtes Objekt
40: // in der Liste gehoert.
41: int Data::Compare(const Data & theOtherData)
42: {
43: if (myValue < theOtherData.myValue)
44: return kIsSmaller;
45: if (myValue > theOtherData.myValue)
46: return kIsLarger;
47: else
48: return kIsSame;
49: }
50:
51: // Vorwaertsdeklarationen
52: class Node;
53: class HeadNode;
54: class TailNode;
55: class InternalNode;
56:
57: // ADT, der das Knotenobjekt in der Liste darstellt
58: // Alle abgeleiteten Klassen müssen Insert und Show redefinieren
59: class Node
60: {
61: public:
62: Node(){}
63: virtual ~Node(){}
64: virtual Node * Insert(Data * theData)=0;
65: virtual void Show() = 0;
66: private:
67: };
68:
69: // Dieser Knoten nimmt das eigentliche Objekt auf.
70: // Hier hat das Objekt den Typ Data.
71: // Bei Besprechung der Templates wird eine
72: // moegliche Verallgemeinerung vorgestellt.
73: class InternalNode: public Node
74: {
75: public:
76: InternalNode(Data * theData, Node * next);
77: ~InternalNode(){ delete myNext; delete myData; }
78: virtual Node * Insert(Data * theData);
79: virtual void Show() {myData->Show(); myNext->Show();} //delegieren!
80:
81: private:
82: Data * myData; // Die Daten selbst
83: Node * myNext; // Zeigt auf naechsten Knoten in der Liste
84: };
85:
86: // Der Konstruktor fuehrt nur Initialisierungen aus.
87: InternalNode::InternalNode(Data * theData, Node * next):
88: myData(theData),myNext(next)
89: {
90: }
91:
92: // Der Kern der Listenkonstruktion. Fuegt man ein
93: // neues Objekt in die Liste ein, wird es an den Knoten
94: // weitergereicht. Dieser ermittelt, wohin das Objekt
95: // gehört, und fügt es in die Liste ein.
96: Node * InternalNode::Insert(Data * theData)
97: {
98:
99: // Ist das neue Objekt groesser oder kleiner als ich?
100: int result = myData->Compare(*theData);
101:
102:
103: switch(result)
104: {
105: // Ist das neue gleich gross, kommt es per Konvention vor das aktuelle
106: case kIsSame: // Gleich zum naechsten case-Zweig
107: case kIsLarger: // Neue Daten vor mir einordnen
108: {
109: InternalNode * dataNode = new InternalNode(theData, this);
110: return dataNode;
111: }
112:
113: // Groesser als ich, also an naechsten Knoten
114: // weiterreichen. ER soll sich drum kuemmern.
115: case kIsSmaller:
116: myNext = myNext->Insert(theData);
117: return this;
118: }
119: return this; // Tribut an MSC
120: }
121:
122:
123: // Endknoten ist einfach eine Markierung
124:
125: class TailNode : public Node
126: {
127: public:
128: TailNode(){}
129: ~TailNode(){}
130: virtual Node * Insert(Data * theData);
131: virtual void Show() { }
132:
133: private:
134:
135: };
136:
137: // Wenn Daten zu mir kommen, muessen sie vor mir eingefuegt werden,
138: // da ich der Endknoten bin und NICHTS nach mir kommt.
139: Node * TailNode::Insert(Data * theData)
140: {
141: InternalNode * dataNode = new InternalNode(theData, this);
142: return dataNode;
143: }
144:
145: // Kopfknoten enthaelt keine Daten, sondern zeigt einfach
146: // auf den Beginn der Liste.
147: class HeadNode : public Node
148: {
149: public:
150: HeadNode();
151: ~HeadNode() { delete myNext; }
152: virtual Node * Insert(Data * theData);
153: virtual void Show() { myNext->Show(); }
154: private:
155: Node * myNext;
156: };
157:
158: // Nach Erzeugen des Kopfknotens erzeugt dieser
159: // sofort den Endknoten.
160: HeadNode::HeadNode()
161: {
162: myNext = new TailNode;
163: }
164:
165: // Vor dem Kopf kommt nichts, also die Daten einfach
166: // an den naechsten Knoten weiterreichen
167: Node * HeadNode::Insert(Data * theData)
168: {
169: myNext = myNext->Insert(theData);
170: return this;
171: }
172:
173: // Ich stehe im Mittelpunkt, mache aber gar nichts.
174: class LinkedList
175: {
176: public:
177: LinkedList();
178: ~LinkedList() { delete myHead; }
179: void Insert(Data * theData);
180: void ShowAll() { myHead->Show(); }
181: private:
182: HeadNode * myHead;
183: };
184:
185: // Bei Geburt erzeuge ich den Kopfknoten.
186: // Er erzeugt den Endknoten.
187: // Eine leere Liste zeigt damit auf den Kopf, dieser
188: // zeigt auf das Ende, dazwischen ist nichts.
189: LinkedList::LinkedList()
190: {
191: myHead = new HeadNode;
192: }
193:
194: // Delegieren, delegieren, delegieren
195: void LinkedList::Insert(Data * pData)
196: {
197: myHead->Insert(pData);
198: }
199:
200: // Rahmenprogramm zum Testen
201: int main()
202: {
203: Data * pData;
204: int val;
205: LinkedList ll;
206:
207: // Anwender zum Erzeugen von Werten auffordern.
208: // Diese Werte in die Liste stellen.
209: for (;;)
210: {
211: cout << "Welcher Wert? (0 zum Beenden): ";
212: cin >> val;
213: if (!val)
214: break;
215: pData = new Data(val);
216: ll.Insert(pData);
217: }
218:
219: // Jetzt Liste durchlaufen und Daten zeigen.
220: ll.ShowAll();
221: return 0; // ll verliert Gueltigkeitsbereich und wird zerstoert!
222: }
Welcher Wert? (0 zum Beenden): 5
Welcher Wert? (0 zum Beenden): 8
Welcher Wert? (0 zum Beenden): 3
Welcher Wert? (0 zum Beenden): 9
Welcher Wert? (0 zum Beenden): 2
Welcher Wert? (0 zum Beenden): 10
Welcher Wert? (0 zum Beenden): 0
2
3
5
8
9
10
Als erstes fällt ein Aufzählungstyp auf, der drei konstante Werte bereitstellt: kIsSmaller
, kIsLarger und kIsSame (kleiner, größer, gleich). Jedes Objekt, das sich in der verketteten
Liste speichern läßt, muß eine Compare()-Methode (Vergleichen) unterstützen.
Diese Konstanten repräsentieren die von der Methode Compare() zurückgegebenen
Werte.
Die Zeilen 28 bis 37 erzeugen zu Demonstrationszwecken die Klasse Data. Die Implementierung
der Methode Compare() steht in den Zeilen 39 bis 49. Ein Data-Objekt
nimmt einen Wert auf und kann sich selbst mit anderen Data-Objekten vergleichen.
Außerdem unterstützt es eine Methode Show(), um den Wert des Data-Objekts anzuzeigen.
Am besten läßt sich die Arbeitsweise der verketteten Liste anhand eines Beispiels verstehen.
Zeile 201 deklariert ein Rahmenprogramm, Zeile 203 einen Zeiger auf ein
Data-Objekt, und Zeile 205 definiert eine lokale verkettete Liste.
Beim Erzeugen der verketteten Liste wird der Konstruktor in Zeile 189 aufgerufen.
Der Konstruktor hat einzig die Aufgabe, ein HeadNode-Objekt (Kopfknoten) zu reservieren
und die Adresse dieses Objekts dem in der verketteten Liste gespeicherten Zeiger
(siehe Zeile 182) zuzuweisen.
Für die Speicherallokation und Erzeugung des HeadNode-Objekts wird der in den Zeilen
160 bis 163 implementierte HeadNode-Konstruktor aufgerufen. Dieser wiederum erzeugt
ein TailNode-Objekt (Endknoten) und weist dessen Adresse dem Zeiger myNext
(Zeiger auf nächsten Knoten) des Kopfknotens zu. Die Erzeugung des TailNode-Objekts
ruft den TailNode-Konstruktor auf (Zeile 128), der inline deklariert ist und keine
Aktionen ausführt.
Durch einfaches Reservieren einer verketteten Liste auf dem Stack werden somit die Liste erzeugt, die Kopf- und Endknoten erstellt und verknüpft. Die sich daraus ergebende Struktur zeigt Abbildung 12.6.
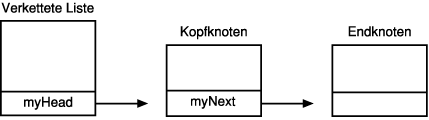
Abbildung 12.6: Die verkettete Liste nach der Erzeugung
Zeile 209 leitet eine Endlosschleife ein. Der Anwender kann jetzt Werte eingeben, die
in die verkettete Liste aufgenommen werden. Er kann beliebig viele Werte eingeben,
mit einer Null zeigt er das Ende der Eingabe an. Der Code in Zeile 213 wertet die eingegebenen
Daten aus. Bei einer Null verläßt das Programm die Schleife.
Ist der Wert ungleich 0, erzeugt Zeile 215 ein neues Data-Objekt, das Zeile 216 in die
Liste einfügt. Nehmen wir zu Demonstrationszwecken an, daß der Anwender den
Wert 15 eingibt. Das bewirkt den Aufruf der Methode Insert() aus Zeile 195.
Die verkettete Liste delegiert sofort die Verantwortlichkeit für das Einfügen des Objekts
an ihren Kopfknoten. Das führt zum Aufruf der Methode Insert() aus Zeile 167.
Der Kopfknoten übergibt die Verantwortlichkeit sofort an den Knoten, auf den myNext
momentan zeigt. In diesem (ersten) Fall zeigt er auf den Endknoten. (Erinnern Sie sich:
Beim Erzeugen des Kopfknotens hat dieser einen Verweis auf einen Endknoten angelegt.)
Das zieht den Aufruf der Methode Insert() aus Zeile 139 nach sich.
Die Methode TailNode::Insert() weiß, daß das übernommene Objekt unmittelbar vor
sich selbst einzufügen ist - das heißt, das neue Objekt kommt direkt vor dem Endknoten
in die Liste. Daher erzeugt die Methode in Zeile 141 ein neues InternalNode-Objekt
und übergibt die Daten und einen Zeiger auf sich selbst. Dies wiederum führt zum
Aufruf des Konstruktors für das InternalNode-Objekt aus Zeile 87.
Der InternalNode-Konstruktor initialisiert lediglich seinen Data-Zeiger mit der Adresse
des übergebenen Data-Objekts und seinen myNext-Zeiger mit der Adresse des übergebenen
Knotens. In diesem Fall zeigt der Knoten auf den Endknoten. (Der Endknoten
hat seinen eigenen this-Zeiger übergeben.)
Nachdem nun der InternalNode-Knoten erstellt ist, wird die Adresse dieses internen
Knotens in Zeile 141 an den Zeiger dataNode zugewiesen und dieser wird wiederum
von der Methode TailNode::Insert() zurückgegeben. Das bringt uns zurück zu HeadNode::Insert()
, wo die Adresse des InternalNode-Knotens dem Zeiger myNext von
HeadNode (in Zeile 169) zugewiesen wird. Schließlich wird die Adresse von HeadNode an
die verkettete Liste zurückgegeben und (in Zeile 197) verworfen. (Das Programm stellt
nichts damit an, da die verkettete Liste bereits die Adresse des Kopfknotens kennt.)
Warum schlägt man sich mit der Rückgabe der Adresse herum, wenn man sie überhaupt
nicht verwendet? Die Methode Insert() ist in der Basisklasse - Node - deklariert.
Den Rückgabewert benötigen andere Implementierungen. Wenn man den Rückgabewert
von HeadNode::Insert() ändert, erhält man einen Compiler-Fehler. Es ist
einfacher, den HeadNode zurückzugeben und die Adresse von der verketteten Liste verwerfen
zu lassen.
Was ist bisher geschehen? Die Daten wurden in die Liste eingefügt. Die Liste hat sie
an den Kopf übergeben. Der Kopf hat diese Daten blindlings dorthin weitergereicht,
wohin der Kopf gerade verweist. In diesem (ersten) Fall hat der Kopf auf das Ende gezeigt.
Der Endknoten hat sofort einen neuen internen Knoten erzeugt und den neuen
Knoten mit einem Verweis auf das Ende initialisiert. Dann hat der Endknoten die
Adresse des neuen Knotens an den Kopf zurückgegeben, und der Kopf hat diesen Zeiger
auf den neuen Knoten in seinen Zeiger myNext eingetragen. Die Daten in der Liste
befinden sich nun am richtigen Platz, wie es Abbildung 12.7 verdeutlicht.
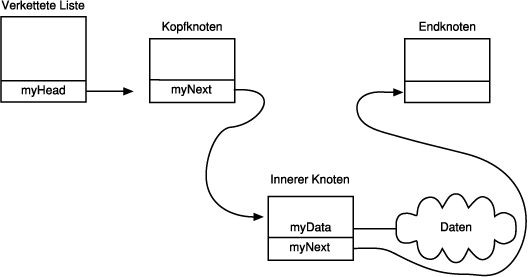
Abbildung 12.7: Die verkettete Liste nach Einfügen des ersten Knotens
Nach dem Einfügen des ersten Knotens setzt das Programm mit Zeile 211 fort, nimmt
einen weiteren Wert entgegen und testet ihn. Nehmen wir an, daß der Anwender den
Wert 3 eingegeben hat. Daraufhin erzeugt Zeile 215 ein neues Data-Objekt, das Zeile
216 in die Liste einfügt.
Auch hier übergibt die Liste in Zeile 197 die Daten an ihren Kopfknoten (HeadNode).
Die Methode HeadNode::Insert() übergibt ihrerseits den neuen Wert an den Knoten,
auf den myNext momentan zeigt. Wie wir wissen, verweist dieser Zeiger jetzt auf den
Knoten mit dem Data-Objekt, dessen Wert gleich 15 ist. Es schließt sich der Aufruf der
Methode InternalNode::Insert() aus Zeile 96 an.
In Zeile 100 veranlaßt InternalNode über den eigenen Zeiger myData, daß das gespeicherte
Data-Objekt (mit dem Wert 15) seine Methode Compare() aufruft und dabei das
neue Data-Objekt (mit dem Wert 3) übergeben wird. Das führt zum Aufruf der in Zeile
41 dargestellten Methode Compare().
Die Methode Compare() vergleicht beide Werte. Da myValue gleich 15 und der Wert
theOtherData.myValue gleich 3 ist, gibt die Methode den Wert kIsLarger zurück. Daraufhin
verzweigt das Programm zu Zeile 109.
Für das neue Data-Objekt wird ein neuer InternalNode erzeugt. Der neue Knoten zeigt
auf das aktuelle InternalNode-Objekt, und die Methode InternalNode::Insert() gibt
die Adresse des neuen InternalNode an HeadNode zurück. Dementsprechend wird der
neue Knoten, dessen Objektwert kleiner als der Objektwert des aktuellen Knotens ist,
in die Liste eingefügt. Die Liste entspricht nun Abbildung 12.8.
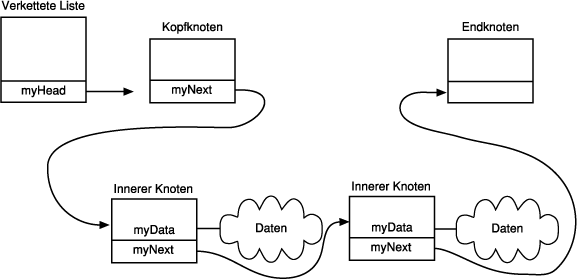
Abbildung 12.8: Die verkettete Liste nach Einfügen des zweiten Knotens
Für den dritten Schleifendurchlauf nehmen wir an, daß der Anwender den Wert 8 eingegeben
hat. Dieser Wert ist größer als 3, aber kleiner als 15 und sollte demnach zwischen
den beiden vorhandenen Knoten eingefügt werden. Der Ablauf entspricht zunächst
genau dem vorherigen Beispiel. Der Vergleich liefert jetzt aber kIsSmaller statt
kIsLarger (weil das Objekt mit dem Wert 3 kleiner als das neue Objekt mit dem Wert 8
ist).
Daraufhin verzweigt die Methode InternalNode::Insert() zu Zeile 116. Statt einen
neuen Knoten zu erzeugen und einzufügen, übergibt InternalNode einfach die neuen
Daten an die Methode Insert() desjenigen Objekts, auf das der Zeiger myNext gerade
zeigt. In diesem Fall erfolgt der Aufruf von InsertNode() für den InternalNode, dessen
Data-Objektwert gleich 15 ist.
Nach einem erneuten Vergleich wird ein neuer InternalNode erzeugt. Dieser zeigt auf
den InternalNode, dessen Data-Objektwert gleich 15 ist. Die Adresse des eingefügten
internen Knotens reicht das Programm an den InternalNode weiter, dessen Data-Objektwert
3 ist (Zeile 116).
Unterm Strich wird der neue Knoten an der richtigen Stelle in die Liste eingefügt.
Wenn Sie die Möglichkeit haben, können Sie schrittweise das Einfügen von Knoten mit Ihrem Debugger nachvollziehen. Dabei läßt sich beobachten, wie diese Methoden einander aufrufen und die Zeiger geeignet angepaßt werden.
Das hier vorgestellte Konzept unterscheidet sich grundlegend von der prozeduralen Programmierung. Bei einem herkömmlichen prozeduralen Programm würde eine steuernde Funktion die Daten untersuchen und die betreffenden Funktionen aufrufen.
In diesem objektorientierten Ansatz erhält jedes Objekt einen genau festgelegten Satz von Verantwortlichkeiten. Die verkettete Liste ist für die Verwaltung des Kopfknotens zuständig. Der Kopfknoten übergibt sofort die neuen Daten dorthin, wohin er gerade zeigt, ohne sich darum zu kümmern, wo das wohl sein könnte.
Sobald der Endknoten Daten erhält, erzeugt er einen neuen Knoten und fügt ihn ein. Der Endknoten handelt nach der Devise: »Wenn diese Daten zu mir gelangen, muß ich sie direkt vor mir einfügen.«
Interne Knoten sind kaum komplizierter. Sie fordern das gespeicherte Objekt auf, sich selbst mit dem neuen Objekt zu vergleichen. Je nach Ergebnis fügen sie entweder das neue Objekt ein oder geben es einfach weiter.
Beachten Sie, daß der interne Knoten keine Ahnung hat, wie der Vergleich auszuführen ist. Die Realisierung des Vergleichs bleibt dem Objekt selbst überlassen. Der interne Knoten fordert die Objekte lediglich zum Vergleich auf und erwartet eine von drei möglichen Antworten. Bei einer bestimmten Antwort wird das Objekt eingefügt, andernfalls reicht es der Knoten weiter und weiß nicht, wohin es schließlich gelangt.
Wer ist also verantwortlich? In einem gut konzipierten objektorientierten Programm ist niemand verantwortlich. Jedes Objekt werkelt still vor sich hin, und im Endeffekt hat man eine gut funktionierende Maschine vor sich.
Das Aufsetzen eigener Array-Klassen ist in vieler Hinsicht vorteilhafter, als die vordefinierten Arrays zu verwenden. Zum einen kann man damit das Überlaufen des Array verhindern. Vielleicht erwägen Sie auch, eine Array-Klasse mit dynamischer Größenanpassung zu implementieren: Zur Zeit seiner Erzeugung hat es nur ein Element, deren Anzahl kann aber im Laufe des Programms zunehmen.
Vielleicht wollen Sie die Elemente des Array sortieren oder anderweitig anordnen. Oder Sie überlegen sich eine ganze Reihe von Array-Varianten. Zu den populärsten gehören:
SparseArray[5] oder SparseArray[200] schreiben,
ohne daß tatsächlich Speicher für 5 oder 200 Werte reserviert wurde.
Durch das Überladen des Index-Operators ([]) können Sie eine verkettete Liste in eine
geordnete Kollektion umwandeln. Durch Ausschluß von doppelten Einträgen, können
Sie eine Kollektion in eine Menge umwandeln. Wenn die Objekte in der Liste aus
Wertepaaren bestehen, können Sie eine verkettete Liste dazu verwenden, ein Wörterbuch
oder ein sparsames Array aufzubauen.
In diesem Kapitel haben Sie gelernt, wie man in C++ Arrays erzeugt. Ein Array ist eine in der Größe festgelegte Sammlung von Objekten, die alle vom gleichen Typ sind.
Arrays führen keine Bereichsprüfung durch. Daher ist es zulässig, über das Ende eines
Array hinauszulesen oder -zuschreiben. Allerdings kann das verheerende Folgen haben.
Die Indizierung von Arrays beginnt bei 0. Ein häufiger Fehler besteht darin, bei
einem Array mit n Elementen in das Element mit dem Index n zu schreiben.
Arrays können eindimensional oder mehrdimensional sein. Für beide Typen von Arrays
lassen sich die Elemente des Arrays initialisieren, sofern das Array vordefinierte
Typen wie int oder Objekte einer Klasse mit Standardkonstruktor enthält.
Arrays und ihre Inhalte kann man auf dem Heap oder auf dem Stack anlegen. Wenn
man ein Array im Heap löscht, sollte man die eckigen Klammern im Aufruf von delete
nicht vergessen.
Array-Namen sind konstante Zeiger auf das jeweils erste Element des Array. Zeiger und Arrays arbeiten mit Zeigerarithmetik, um das nächste Element in einem Array zu lokalisieren.
Sie können verkettete Listen erstellen, um Kollektionen zu verwalten, deren Größe Sie zur Kompilierzeit noch nicht kennen. Aufbauend auf einer verketteten Liste können Sie eine beliebige Anzahl von komplexen Datenstrukturen erzeugen.
Strings sind Arrays von Zeichen oder Variablen vom Typ char. C++ stellt spezielle
Funktionen für die Verwaltung von char-Arrays bereit. Dazu gehört die Initialisierung
der Strings mit Zeichenfolgen, die in Anführungszeichen eingeschlossen sind.
Frage:
Was passiert, wenn ich in das Element 25 eines 24-elementigen Array
schreibe?
Antwort:
Der Schreibvorgang findet in einem außerhalb des Array liegenden Speicherbereich
statt und kann damit verheerende Folgen im Programm haben.
Frage:
Was ist in einem nicht initialisierten Array-Element gespeichert?
Antwort:
Jeweils das, was sich gerade im Speicher befindet. Die Ergebnisse bei der Verwendung
dieses Elements ohne vorherige Zuweisung eines Wertes sind nicht
vorhersehbar.
Frage:
Kann ich Arrays zusammenfassen?
Antwort:
Ja. Einfache Arrays kann man mit Hilfe von Zeigern zu einem neuen, größeren
Array kombinieren. Bei Strings kann man mit den integrierten Funktionen
wie zum Beispiel strcat() arbeiten, um Zeichenfolgen zu verketten.
Frage:
Warum soll ich eine verkettete Liste erzeugen, wenn auch ein Array
funktioniert?
Antwort:
Ein Array muß eine feste Größe haben, während sich eine verkettete Liste dynamisch
zur Laufzeit in der Größe ändern kann.
Frage:
Warum sollte ich jemals vordefinierte Arrays verwenden, wenn ich
selbst eine bessere Array-Klasse implementieren kann?
Antwort:
Vordefinierte Arrays lassen sich schnell und problemlos einsetzen.
Frage:
Muß eine String-Klasse einen char * verwenden, um den Inhalt eines
Strings aufzunehmen?
Antwort:
Nein. Sie kann jeden beliebigen vom Entwickler vorgesehenen Speicherplatz
verwenden.
Der Workshop enthält Quizfragen, die Ihnen helfen sollen, Ihr Wissen zu festigen, und Übungen, die Sie anregen sollen, das eben Gelernte umzusetzen und eigene Erfahrungen zu sammeln. Versuchen Sie, das Quiz und die Übungen zu beantworten und zu verstehen, bevor Sie die Lösungen in Anhang D lesen und zur Lektion des nächsten Tages übergehen.
EinArray[25]?
EinArray[10][5][20]?
0 initialisiert.
Node-Klasse, die Integer-Werte aufnimmt.
unsigned short EinArray[5][4];
for (int i = 0; i<4; i++)
for (int j = 0; j<5; j++)
EinArray[i][j] = i+j;
unsigned short EinArray[5][4];
for (int i = 0; i<=5; i++)
for (int j = 0; j<=4; j++)
EinArray[i][j] = 0;
© Markt+Technik Verlag, ein Imprint der Pearson Education Deutschland GmbH